
Introduction
Traditionally in financial services, probabilistic models have been used to underwrite risks of payment processing, while identity verification primarily relies on government-issued forms of identification, such as government IDs and Social Security Numbers (in the U.S.).
These models can be somewhat effective in mitigating transaction fraud, but do not directly tackle identity theft¹. In addition, these models are prone to becoming outdated, since identity theft typologies and datasets evolve over time.
This blog showcases a novel approach to identity verification, with the goal of accomplishing the following:
- Building a globally generalizable verification stack that targets identity theft as its vector, and uses enhanced due diligence to further refine decisioning.
- Building a semi-automated retraining pipeline that reduces the likelihood that the models become outdated over time.
Why This Problem?
Relying on government-issued identification sources alone present two issues:
- They can be exclusionary, since not everyone has easy access to government-issued identification.
- They are localized, meaning they are not easily transferable to an international customer base.
Our goal is to build a globally-applicable model that can predict how likely a person is who they said they are, allowing us and developers building on top of Synapse to rely less on government-issued identification sources whenever they are not required by regulation or considered best practice².
ID Score is premised on the idea that individuals leave behind a digital trail as they go about their lives, creating a robust tapestry of contact, social, and demographic information. By comparison, fraudulent or synthetic identities only have limited or inconsistent information. Synapse uses the digital “crumbs” that everyone leaves behind to verify a user’s identity. With only a few data points — those “crumbs” — ID Score predicts how likely it is that a user is who they say they are.
We enrich the data with various data providers and then generate secondary/derived features and embeddings on which a supervised model is trained.
ID Score allows our platforms to onboard customers with universal document requirements that are easy for users to fulfill, while still mitigating risk, blocking fake accounts, and effectively helping our compliance team and EDD models (video auth, ID verification, etc,) find needles in a haystack³.
Under the hood
The Model
ID Score is a supervised model that is built based on historical user data. It uses the user’s base document (name, physical address, phone number, email address, and IP address) to enrich and generate secondary features and embeddings, which then are fed into the model for prediction.
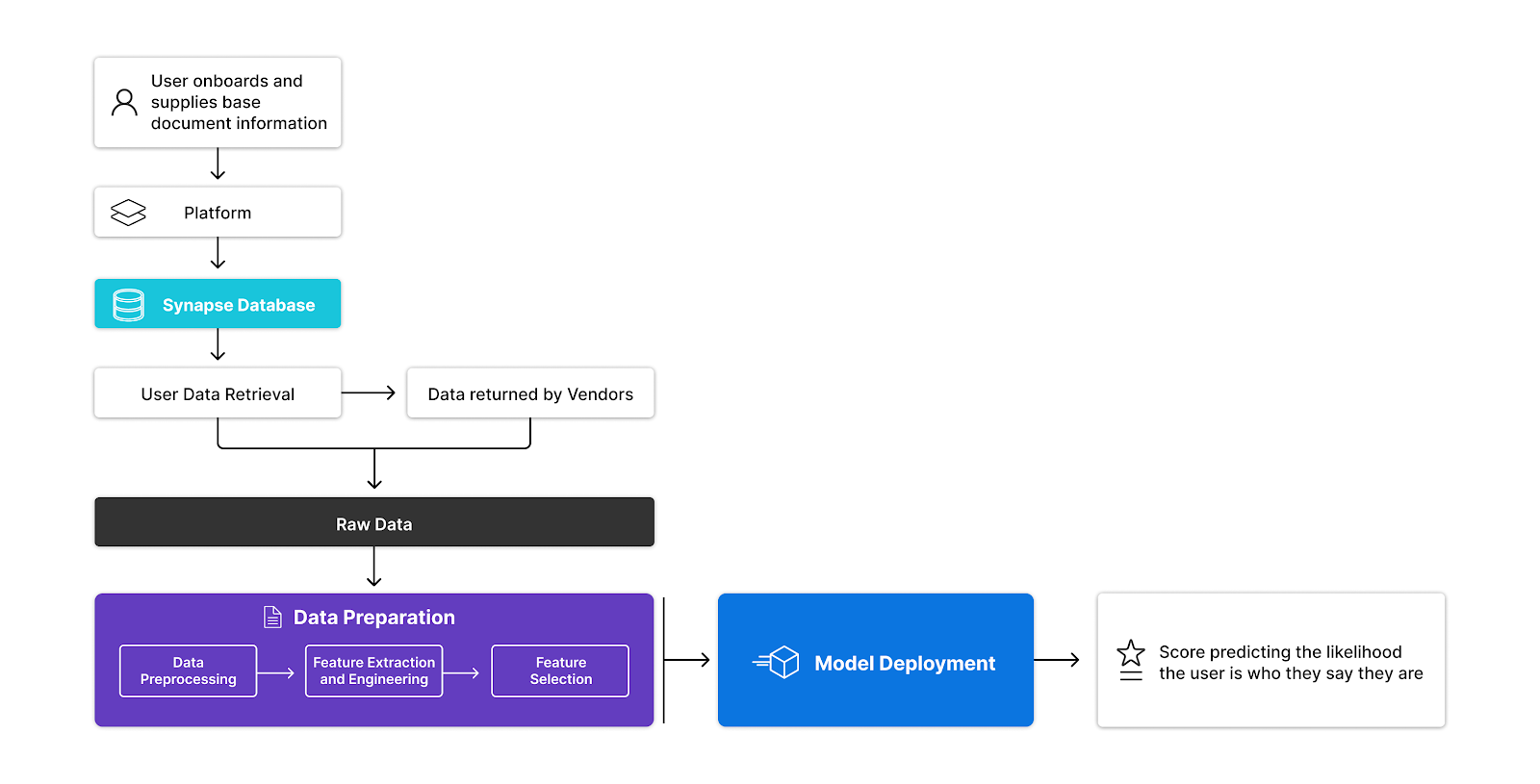
In turn, we use that score to determine whether we should request additional documentation from the user, so that we can increase our confidence level that the user is who they say they are. For users whose scores are middling or moderately low, we request only a small amount of additional information. For users whose scores are very low, we request higher amounts of documentation or information. We refer to this as the EDD Pyramid⁴.

The EDD thresholds are encoded into a platform’s governance-level controls, and the specific user requirements and the thresholds at which they are required vary based on the platform’s use case and the associated regulatory requirements (that is, if a platform’s use case already requires it to collect government IDs and SSNs from its users, the Pyramid is adjusted appropriately).
Semi-Automated Retraining
To ensure that the model does not become outdated, it is crucial that the retraining pipeline be as automated as possible. We accomplish this by containerizing our retraining pipeline, with the goal of retraining the model as frequently as needed and automatically propagating the best model to production.
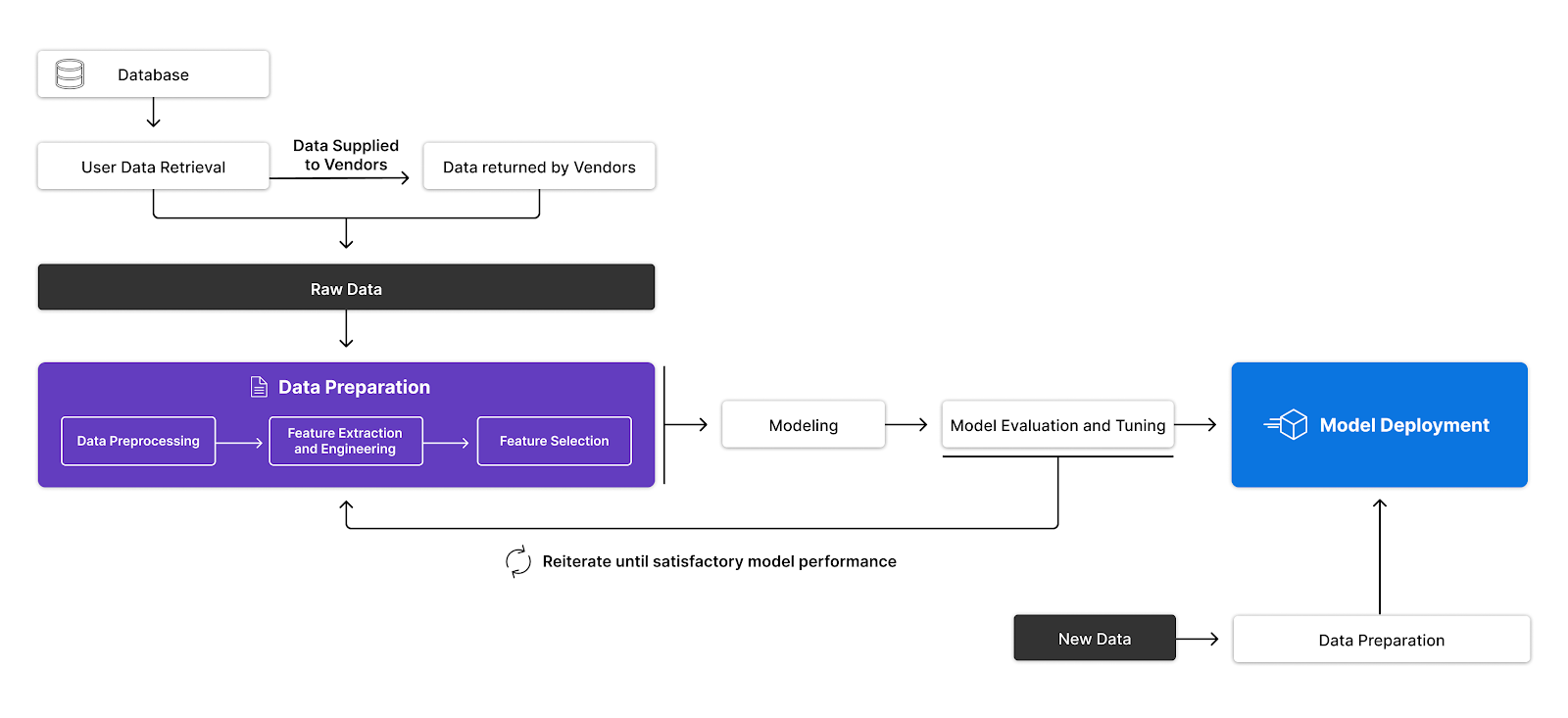
Each feature is assigned a theoretical weight⁵ (or “feature importance”), which allows us to quantify how similar a new user is to previously-seen fraudulent users. As the dataset evolves, the feature importances adjusts, keeping the model precision high with the evolving data.
By using a semi-automated retraining pipeline, encoding patterns are constantly evolving and are a reflection of the latest data on which the model has been trained. This is key to ensuring we have the most up-to-date embedding patterns in our model.
What’s Next
ID Score is a stepping stone for improving the ID Verification experience for everyone who is interacting with the Synapse infrastructure. We will be using this as a foundation for two more products:
Non-US KYC
As we take Synapse to other countries, ID Score is crucial because it provides us a foundation for identity verification in every country we expand into as now identity verification is not reliant on locally issued documents, making the infrastructure more resilient to identity theft from day one in any country.
Business KYC
For business users, we have two main categories of information: information about the business, and information about the Ultimate Beneficial Owner(s) (UBOs). With ID Score as it currently stands, the model is capable of assessing UBOs.
The next challenge is to build enrichment methods for validating business’ industry of operation, negative news, and a few other attributes to further enhance the capabilities of ID score for businesses.
On top of these two products, ID Score is our first attempt at building an automated retraining pipeline. We will continue to enhance this part of the infrastructure and propagate these learnings to our other machine learning products overtime. Stay tuned!
Thanks to Yona Koch-Fienberg for collaborating on the project and the blog.
–––
[1] Although there is an overlap in stolen identities and transactional fraud, it’s important to note the differences in both. For instance, you are allowed to not originate a transaction on behalf of a user if you deem it’s high risk with an intent to defraud, but you cannot deny them access to a bank account or core financial instruments for that reason alone. This is why it’s important to build identity verification solutions outside of transactional risk underwriting.
[2] We will continue to collect and verify all legally-required documentation from users as part of Synapse’s commitment to fulfilling the requirements of the Bank Secrecy Act, the USA PATRIOT Act, and all other relevant regulation, to the same standard as our partner banks.
[3] Reducing back office work is quite important, as it is truly the only way to democratize access to high-class financial products to the masses.
[4] The documentation that the user sends for those additional Enhanced Due Diligence requests feeds into our existing identity verification pipelines, including our physical document verification models (Newton) and our data aggregation models, including SSN verification (Sherlock). It’s important to automate EDD processes as much as possible, in order to reduce the back office costs associated with operating financial products.
[5] The weights can be understood like this: if the user is very similar to a fraudulent user that the model has previously seen, then the model is less confident that the person is who they say they are, and so it assigns to the user a lower score. Because the user has a low score, the user is prompted to submit additional types of KYC documentation or information, and our other EDD and identity verification models are called to verify that documentation or information.

